
요르딩딩
CHAPTER 8. 그래프 이론 본문
728x90
반응형
<서로소 집합>
- 서로소 집합 자료구조 : 서로수 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조
- 서로소 집합 자료구조는 union과 find 연산으로 조작할 수 있다.
- 합집합(Union): 두 개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산
- 찾기(Find): 특정한 원소가 속한 집합이 어떤 집합인지 알려주는 연산
- 과정
1. 합집합(Union) 연산을 확인하여, 서로 연결된 두 노드 A, B를 확인한다
- A와 B의 루트 노드 A′, B′를 각각 찾는다
- A′를 B′의 부모 노드로 설정한다
2. 모든 합집합(Union) 연산을 처리할 때까지 1번의 과정을 반복한다
import java.util.*;
public class Main {
// 노드의 개수(V)와 간선(Union 연산)의 개수(E)
// 노드의 개수는 최대 100,000개라고 가정
public static int v, e;
public static int[] parent = new int[100001]; // 부모 테이블 초기화하기
// 특정 원소가 속한 집합을 찾기
public static int findParent(int x) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (x == parent[x]) return x;
return findParent(parent[x]);
}
// 두 원소가 속한 집합을 합치기
public static void unionParent(int a, int b) {
a = findParent(a);
b = findParent(b);
if (a < b) parent[b] = a;
else parent[a] = b;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
v = sc.nextInt();
e = sc.nextInt();
// 부모 테이블상에서, 부모를 자기 자신으로 초기화
for (int i = 1; i <= v; i++) {
parent[i] = i;
}
// Union 연산을 각각 수행
for (int i = 0; i < e; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
unionParent(a, b);
}
// 각 원소가 속한 집합 출력하기
System.out.print("각 원소가 속한 집합: ");
for (int i = 1; i <= v; i++) {
System.out.print(findParent(i) + " ");
}
System.out.println();
// 부모 테이블 내용 출력하기
System.out.print("부모 테이블: ");
for (int i = 1; i <= v; i++) {
System.out.print(parent[i] + " ");
}
System.out.println();
}
}
< 서로소 집합 자료구조: 기본적인 구현 방법의 문제점 >

< 해결 방법 >
- 찾기(Find) 함수를 최적화하기 위한 방법으로 경로 압축(Path Compression)을 이용할 수 있다
- 과정
- 찾기(Find) 함수를 재귀적으로 호출한 뒤에 부모 테이블 값을 바로 갱신한다
- 경로 압축 기법을 적용하면 각 노드에 대하여 찾기(Find) 함수를 호출한 이후에 해당 노드의 루트 노드가
바로 부모 노드가 된다 - 동일한 예시에 대해서 모든 합집합(Union) 함수를 처리한 후 각 원소에 대하여 찾기(Find) 함수를 수행하면
다음과 같이 부모 테이블이 갱신된다 - 기본적인 방법에 비하여 시간 복잡도가 개선된다
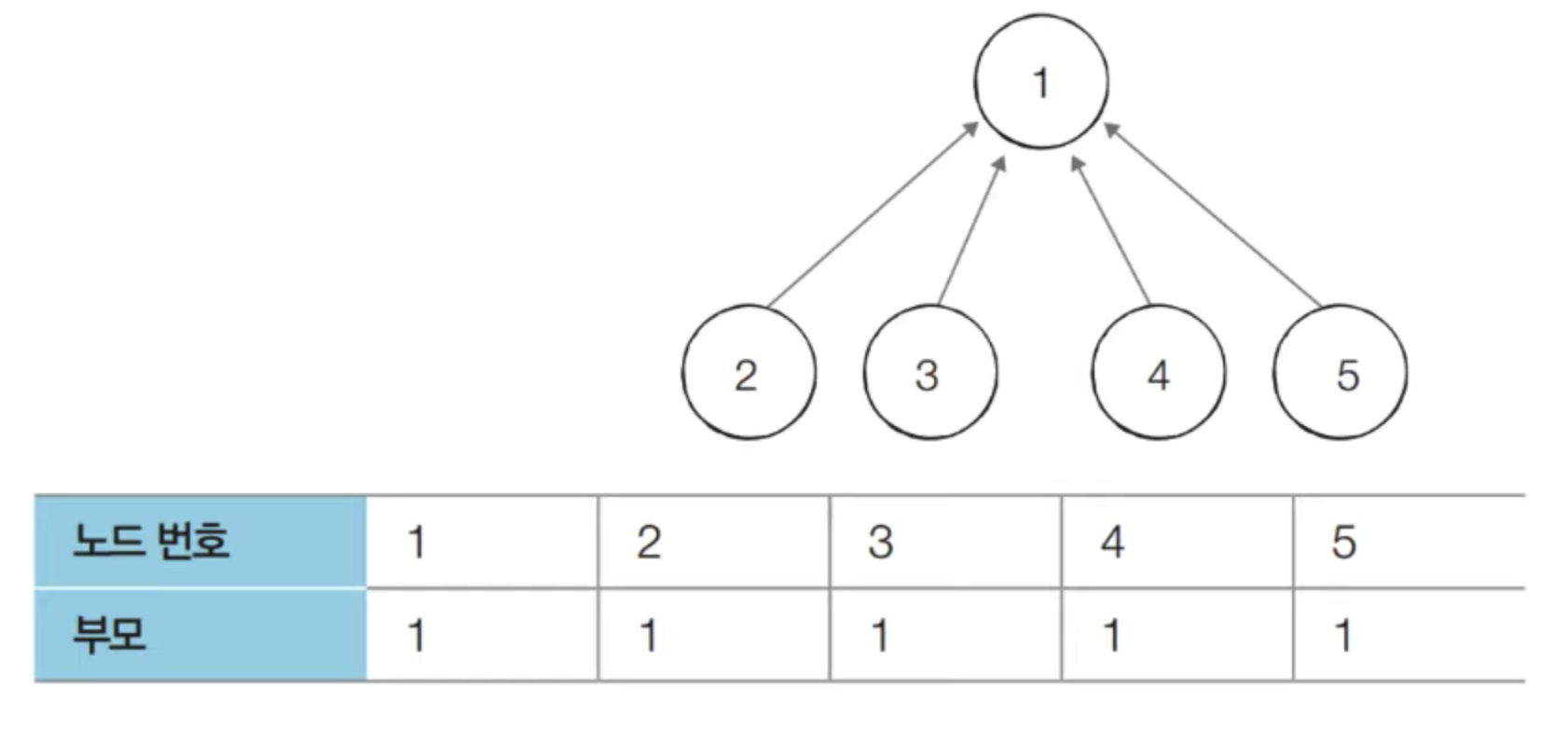
- 경로 압축 : 개선된 서로소 집합 알고리즘 소스코드
import java.util.*;
public class Main {
// 노드의 개수(V)와 간선(Union 연산)의 개수(E)
// 노드의 개수는 최대 100,000개라고 가정
public static int v, e;
public static int[] parent = new int[100001]; // 부모 테이블 초기화하기
// 특정 원소가 속한 집합을 찾기
public static int findParent(int x) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (x == parent[x]) return x;
return parent[x] = findParent(parent[x]);
}
// 두 원소가 속한 집합을 합치기
public static void unionParent(int a, int b) {
a = findParent(a);
b = findParent(b);
if (a < b) parent[b] = a;
else parent[a] = b;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
v = sc.nextInt();
e = sc.nextInt();
// 부모 테이블상에서, 부모를 자기 자신으로 초기화
for (int i = 1; i <= v; i++) {
parent[i] = i;
}
// Union 연산을 각각 수행
for (int i = 0; i < e; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
unionParent(a, b);
}
// 각 원소가 속한 집합 출력하기
System.out.print("각 원소가 속한 집합: ");
for (int i = 1; i <= v; i++) {
System.out.print(findParent(i) + " ");
}
System.out.println();
// 부모 테이블 내용 출력하기
System.out.print("부모 테이블: ");
for (int i = 1; i <= v; i++) {
System.out.print(parent[i] + " ");
}
System.out.println();
}
}<서로소 집합을 활용한 사이클 판별>
- 간선에 방향성이 없는 무향 그래프에서만 적용이 가능하다.
- 간선의 개수가 E개 일때, 모든 간선을 하나씩 확인하며, 매 간선에 대하여 union 및 find 함수를 호출하는 방식으로 동작한다.
- 과정
1. 각 간선을 하나씩 확인하며 두 노드의 루트 노드를 확인한다
- 루트 노드가 서로 다르다면 두 노드에 대하여 합집합(Union) 연산을 수행한다
- 루트 노드가 서로 같다면 사이클(Cycle)이 발생한 것이다
2. 그래프에 포함되어 있는 모든 간선에 대하여 1번 과정을 반복한다
- 서로소 집합을 활용한 사이클 판별 소스코드
import java.util.*;
public class Main {
// 노드의 개수(V)와 간선(Union 연산)의 개수(E)
// 노드의 개수는 최대 100,000개라고 가정
public static int v, e;
public static int[] parent = new int[100001]; // 부모 테이블 초기화하기
// 특정 원소가 속한 집합을 찾기
public static int findParent(int x) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (x == parent[x]) return x;
return parent[x] = findParent(parent[x]);
}
// 두 원소가 속한 집합을 합치기
public static void unionParent(int a, int b) {
a = findParent(a);
b = findParent(b);
if (a < b) parent[b] = a;
else parent[a] = b;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
v = sc.nextInt();
e = sc.nextInt();
// 부모 테이블상에서, 부모를 자기 자신으로 초기화
for (int i = 1; i <= v; i++) {
parent[i] = i;
}
boolean cycle = false; // 사이클 발생 여부
for (int i = 0; i < e; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
// 사이클이 발생한 경우 종료
if (findParent(a) == findParent(b)) {
cycle = true;
break;
}
// 사이클이 발생하지 않았다면 합집합(Union) 연산 수행
else {
unionParent(a, b);
}
}
if (cycle) {
System.out.println("사이클이 발생했습니다.");
}
else {
System.out.println("사이클이 발생하지 않았습니다.");
}
}
}
<(최소)신장트리>
- 하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프
- 최소 비용으로 만들 수 있는 신장트리를 찾는 알고리즘을 '최소 신장 트리 알고리즘'이라고 한다.
- 대표적으로는 다이나믹 알고리즘으로 분류되는 '크루스칼 알고리즘'이 있다.
- 크루스칼 알고리즘의 핵심 원리는 가장 거리가 짧은 간선부터 차례대로 집합을 추가하면 된다는 것이다. 다만, 사이클을 발생시키는 간선은 제외하고 연결한다.
- 간선의 개수 = 노드의 개수 -1
- 과정
1. 간선 데이터를 비용에 따라 오름차순으로 정렬한다
2. 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인한다
- 사이클이 발생하지 않는 경우 최소 신장 트리에 포함시킨다
- 사이클이 발생하는 경우 최소 신장 트리에 포함시키지 않는다
3. 모든 간선에 대하여 2번의 과정을 반복한다
- 시간복잡도
- 간선의 개수가 E개 일때, O(ElogE)
- 왜냐하면, 크루스칼 알고리즘에서 시간이 가장 오래 걸리는 부분이 간선을 정렬하는 작업이며, E개의 데이터를 정렬했을 때의 시간 복잡도는 O(ElogE) 이기 때문이다.
크루스칼 알고리즘 소스코드
import java.util.*;
class Edge implements Comparable<Edge> {
private int distance;
private int nodeA;
private int nodeB;
public Edge(int distance, int nodeA, int nodeB) {
this.distance = distance;
this.nodeA = nodeA;
this.nodeB = nodeB;
}
public int getDistance() {
return this.distance;
}
public int getNodeA() {
return this.nodeA;
}
public int getNodeB() {
return this.nodeB;
}
// 거리(비용)가 짧은 것이 높은 우선순위를 가지도록 설정
@Override
public int compareTo(Edge other) {
if (this.distance < other.distance) {
return -1;
}
return 1;
}
}
public class Main {
// 노드의 개수(V)와 간선(Union 연산)의 개수(E)
// 노드의 개수는 최대 100,000개라고 가정
public static int v, e;
public static int[] parent = new int[100001]; // 부모 테이블 초기화하기
// 모든 간선을 담을 리스트와, 최종 비용을 담을 변수
public static ArrayList<Edge> edges = new ArrayList<>();
public static int result = 0;
// 특정 원소가 속한 집합을 찾기
public static int findParent(int x) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (x == parent[x]) return x;
return parent[x] = findParent(parent[x]);
}
// 두 원소가 속한 집합을 합치기
public static void unionParent(int a, int b) {
a = findParent(a);
b = findParent(b);
if (a < b) parent[b] = a;
else parent[a] = b;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
v = sc.nextInt();
e = sc.nextInt();
// 부모 테이블상에서, 부모를 자기 자신으로 초기화
for (int i = 1; i <= v; i++) {
parent[i] = i;
}
// 모든 간선에 대한 정보를 입력 받기
for (int i = 0; i < e; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
int cost = sc.nextInt();
edges.add(new Edge(cost, a, b));
}
// 간선을 비용순으로 정렬
Collections.sort(edges);
// 간선을 하나씩 확인하며
for (int i = 0; i < edges.size(); i++) {
int cost = edges.get(i).getDistance();
int a = edges.get(i).getNodeA();
int b = edges.get(i).getNodeB();
// 사이클이 발생하지 않는 경우에만 집합에 포함
if (findParent(a) != findParent(b)) {
unionParent(a, b);
result += cost;
}
}
System.out.println(result);
}
}- < 문제풀때 >
- ArrayList<Edge> edges (distance, nodeA, nodeB) : 노드 리스트 (정렬)
- parent (처음에 자신을 루트로 갱신) : [ (x=1), (x=2), (x=3) ...]
- result (최소비용) : UnionParent할때 마다 result += cost
<위상정렬>
- 방향 그래프의 모든 노드를 '방향성에 거스르지 않도록 순서대로 나열하는 것'이다.
- 일종의 정렬 알고리즘이다.
- 사이클이 없어야 한다.
- 과정
1. 진입차수가 0인 노드를 큐에 넣는다.
- 큐가 빌때까지 다음의 과정을 반복한다.
- 큐에서 원소를 꺼내 해당 노드에서 출발하는 간선을 그래프에서 제거한다.
2. 새롭게 진입차수가 0이 된 노드를 큐에 넣는다.
- 시간복잡도 : O(V + E)
- 위상 정렬을 위해 차례대로 모든 노드를 확인하며 각 노드에서 나가는 간선을 차레대로 제거해야 한다.
import java.util.*;
public class Main {
// 노드의 개수(V)와 간선의 개수(E)
// 노드의 개수는 최대 100,000개라고 가정
public static int v, e;
// 모든 노드에 대한 진입차수는 0으로 초기화
public static int[] indegree = new int[100001];
// 각 노드에 연결된 간선 정보를 담기 위한 연결 리스트 초기화
public static ArrayList<ArrayList<Integer>> graph = new ArrayList<ArrayList<Integer>>();
// 위상 정렬 함수
public static void topologySort() {
ArrayList<Integer> result = new ArrayList<>(); // 알고리즘 수행 결과를 담을 리스트
Queue<Integer> q = new LinkedList<>(); // 큐 라이브러리 사용
// 처음 시작할 때는 진입차수가 0인 노드를 큐에 삽입
for (int i = 1; i <= v; i++) {
if (indegree[i] == 0) {
q.offer(i);
}
}
// 큐가 빌 때까지 반복
while (!q.isEmpty()) {
// 큐에서 원소 꺼내기
int now = q.poll();
result.add(now);
// 해당 원소와 연결된 노드들의 진입차수에서 1 빼기
for (int i = 0; i < graph.get(now).size(); i++) {
indegree[graph.get(now).get(i)] -= 1;
// 새롭게 진입차수가 0이 되는 노드를 큐에 삽입
if (indegree[graph.get(now).get(i)] == 0) {
q.offer(graph.get(now).get(i));
}
}
}
// 위상 정렬을 수행한 결과 출력
for (int i = 0; i < result.size(); i++) {
System.out.print(result.get(i) + " ");
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
v = sc.nextInt();
e = sc.nextInt();
// 그래프 초기화
for (int i = 0; i <= v; i++) {
graph.add(new ArrayList<Integer>());
}
// 방향 그래프의 모든 간선 정보를 입력 받기
for (int i = 0; i < e; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
graph.get(a).add(b); // 정점 A에서 B로 이동 가능
// 진입 차수를 1 증가
indegree[b] += 1;
}
topologySort();
}
}- < 문제풀때 >
- graph : 2차원 리스트
(now) [(i=1) (i=2) (i=3)...]
(1) [2, 3 ] --- (1->2), (1->3)
(2) [ ]
(3) [4, 5 ] --- (3->4), (3->5)
- indegree : [ (i=1), (i=2), (i=3) ]
[null, 1, 1, 1, 1]
- Queue : 진입차수가 0인거 offer()
참고 : 이것이 코딩테스트다.
https://freedeveloper.tistory.com/387?category=888096
로직암기
| No | 최소신장트리 | 위상정렬 |
| class Edge v,e int[] Parent ArrayList edges int result =0 |
v,e int[] indegree ArrayList(ArrayList<Integer>) graph |
|
| 1 | class Edge | topologySort |
| 2 | findParent | ArrayList result |
| 3 | unionParent | 큐, 삽입 |
| 4 | parent[i] = i | indegree ==0 |
| 5 | edges.add(new Edge(cost, a, b)) | while(!q.isEmpty()) |
| 6 | Collections.sort(edges) | poll |
| 7 | for(edges.size) | result.add |
| 8 | findParent(a) != (b) | for(size) |
| 9 | unionParent | indegree[] -=1 |
| 10 | result += cost | indegree[] =0 |
| 11 | - | 큐삽입 |
| 12 | - | for(출력) |
| 13 | - | graph.add(new ArrayList<>) |
| 14 | - | graph.get(a).add(b) |
| 15 | - | indegree[] +=1 |
728x90
반응형
'[코딩테스트] > 이론' 카테고리의 다른 글
| Chapter 9. 최단경로 (0) | 2022.02.14 |
|---|---|
| CHAPTER 3. DFS/BFS (0) | 2022.02.10 |
| CHAPTER 4. 정렬 (0) | 2022.02.03 |
| 플로이드 워셜 알고리즘 (0) | 2022.01.17 |
| 다익스트라 최단거리 알고리즘 (0) | 2022.01.10 |
'[코딩테스트]/이론' Related Articles
more

Comments